학술대회 및 수상: 신준호, 장원혁, 정상훈, 김동재, 김동현, 문형빈. (2025). 사용자 입력 데이터의 정형화 및 피드백 자동화를 위한 챗봇 설계. 한국자료분석학회지 (Journal of the Korean Data Analysis Society), 동계학술대회. 포스터 장려상 수상작.
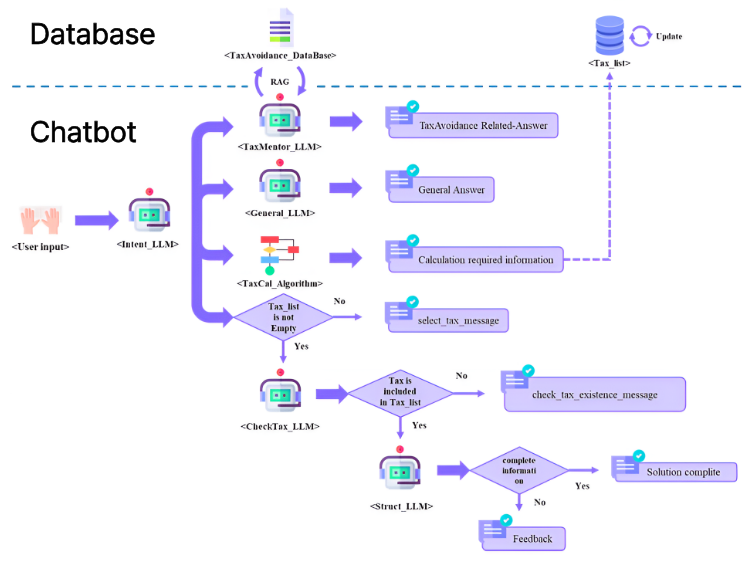
Figure 1. Flowchart
강건한 AI 에이전트를 구축하려면 자연어 형태의 비정형 사용자 입력을 시스템이 처리할 수 있는 정형화된 프로세스와 매끄럽게 연결해야 합니다. 본 연구는 (주)뉴아이의 세금 솔루션 시뮬레이션을 대상으로 이를 실현하는 실용적인 다중 LLM 아키텍처를 제안합니다.
📌 문제 정의: 규칙 기반 챗봇의 한계와 복잡한 도메인
기존의 규칙 기반 RPA 챗봇은 정해진 시나리오대로만 작동하기 때문에, 대화형 방식의 인간 입력이 가지는 동적인 특성을 처리하는 데 한계가 있습니다. 특히 양도소득세와 같이 복잡한 도메인에서는 사용자가 필수 정보를 자주 누락하거나 복합적인 질문을 던지기 때문에, 기존의 경직된 시스템은 정상적으로 기능하기 어렵습니다.
⚙️ 연구 방법론: 다중 LLM 오케스트레이션 및 능동적 피드백
이러한 문제를 해결하기 위해, 비정형 데이터를 정형화하고 누락된 정보를 식별하여 사용자에게 능동적으로 피드백하는 차별화된 챗봇 시스템을 설계했습니다:
- Intent_LLM: 사용자의 텍스트를 분석하여 그 의도를 세금계산, 세금질문, 세금정보기입, 일반질문의 4가지 범주로 동적으로 분류합니다.
- Struct_LLM (데이터 정형화): 분류된 의도를 바탕으로 자연어 맥락에서 필수 변수들을 추출하고, 이를 백엔드 시스템이 즉시 연산할 수 있도록 JSON 형식으로 엄격하게 구조화합니다.
- CheckTax_LLM 및 능동적 피드백: 데이터 정형화 과정에서 필수 정보의 누락을 감지합니다. 예를 들어, 사용자가 부동산 매도 사실만 입력하고 ‘필요경비’를 누락한 경우, 시스템은 이를 스스로 식별하여 사용자에게 필요경비 입력을 유도하는 능동적인 피드백을 수행합니다.
🚀 연구의 시사점: 고신뢰도 데이터 정형화의 실증
자체 구축한 검증 데이터셋을 활용하여 분류 성능을 평가한 결과, Intent_LLM은 Macro F1-score 0.94를, Struct_LLM은 F1-Score 0.9583을 달성하며 제안 모델의 높은 신뢰성과 실효성을 입증했습니다.
본 연구는 세무/부동산과 같이 고도로 복잡한 정보를 다루는 도메인에서, LLM이 사용자의 의도를 유연하게 추론하고, JSON 기반의 엄격한 데이터 정형화를 수행하며, 나아가 스스로 누락된 정보를 해결(Feedback)할 수 있음을 실증했다는 데 큰 의의가 있습니다.