Conference & Awards: Shin, J., Jang, W., Jeong, S., Kim, D., Kim, D., & Moon, H. (2025). Chatbot Design for Structuring and Feedback Automation of User Input Data. Journal of the Korean Data Analysis Society. Winter Conference. Awarded the Poster Encouragement Award.
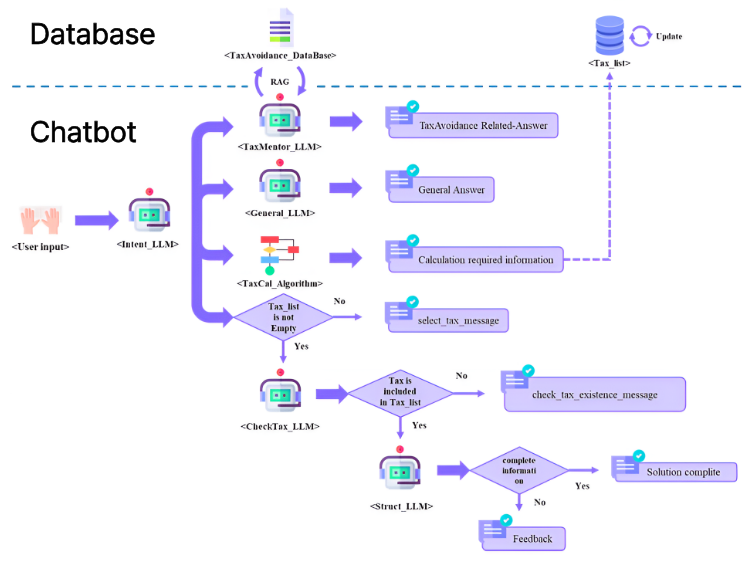
Figure 1. Flowchart
To build robust AI agents, we must seamlessly connect unstructured human input with structured systemic processes. This project proposes a practical LLM architecture to achieve this within the complex domain of taxation, specifically targeting a tax solution simulation by New-I Co., Ltd.
📌 The Problem: Rigidity of Rule-based Chatbots
Traditional rule-based RPA (Robotic Process Automation) chatbots operate strictly on predefined rules. While accurate, they cannot flexibly handle the dynamic, conversational nature of human input. In complex domains like real estate tax, users often omit necessary information or ask ambiguous questions, causing rigid systems to fail.
⚙️ The Method: Multi-LLM Orchestration & Proactive Feedback
To overcome this, we designed a dynamic chatbot system that utilizes multiple LLMs to structure unstructured data and automate missing information feedback:
- Intent_LLM: Analyzes the user’s text to dynamically classify their intent into four strict categories: Tax Calculation, Tax Inquiry, Tax Info Entry, or General Inquiry.
- Struct_LLM (Information Extraction): Isolates the necessary variables from the natural language context based on the identified intent and formats them strictly into JSON, acting as a direct bridge to the backend calculation engine.
- CheckTax_LLM & Proactive Feedback: During the structuring process, the system actively identifies omitted mandatory variables. For example, if a user asks for capital gains tax calculation but omits ‘necessary expenses (필요경비)’, the system detects this gap and proactively generates conversational feedback to request the missing data.
🚀 The Impact: High-Reliability Data Structuring
Using a custom validation dataset, the architecture demonstrated exceptional performance. The Intent_LLM achieved a Macro F1-score of 0.94, while the Struct_LLM reached an F1-Score of 0.9583.
This research proves the practical feasibility of deploying advanced conversational agents that can simultaneously infer human intent, perform rigorous JSON data structuring, and autonomously resolve missing information in highly complex domains.